

The path to capable small language models runs through efficiency, not scale. While frontier labs race toward trillion-parameter models, a parallel movement has proven that smaller, specialized models can match or exceed frontier performance for specific domains—at a fraction of the cost. The evidence is now overwhelming: DeepSeek R1, trained on constrained hardware with innovative techniques, matches OpenAI's o1 on reasoning benchmarks. Microsoft's Phi-4-reasoning outperforms models 20x its size. Meta's Llama 3.2 brings capable 1B and 3B models to edge devices.
This shift creates a massive market opportunity. Within this, thousands of enterprises will deploy multiple specialized models—for clinical documentation, legal research, financial analysis, and real-time industrial control—creating demand for fine-tuning, deployment, and continuous optimization infrastructure.
Our thesis focuses on four durable sources of value creation:
- Workflow-embedded applications with proprietary data flywheels: Verticalized enterprises have compelling reasons to adopt SLMs—cost, latency, privacy, and compounding data advantages. Research confirms that data quality outweighs quantity, and synthetic data techniques can amplify proprietary datasets. The persistent math/reasoning gap in generalist models creates structural opportunities for domain-specific specialization.
- Enterprise packaging that captures value beyond commoditizing algorithms: Open-source SLMs commoditize the weights, but enterprises need more than algorithms—they need compliance, integration, on-device personalization, and privacy-preserving deployment. Winners build platforms, not just models.
- Hardware-architecture co-design that creates durable differentiation: SLM performance depends critically on how architecture choices interact with specific hardware. Companies mastering NPU optimization, quantization-aware training, and inference scaling laws have defensible advantages that pure algorithm players cannot replicate.
- Orchestration and edge-cloud collaboration as control plane: The future isn't SLM or LLM—it's intelligent routing between them. The orchestration layer that manages speculative decoding, cascade routing, and cost-quality tradeoffs becomes strategic infrastructure.
We hosted an SLM hackathon with AWS in November 2025 that validated these themes in practice—teams built functional prototypes on AWS Trainium demonstrating real-time reasoning, clinical documentation, and agentic systems in under 8 hours.
The SLM Movement: Key Milestones
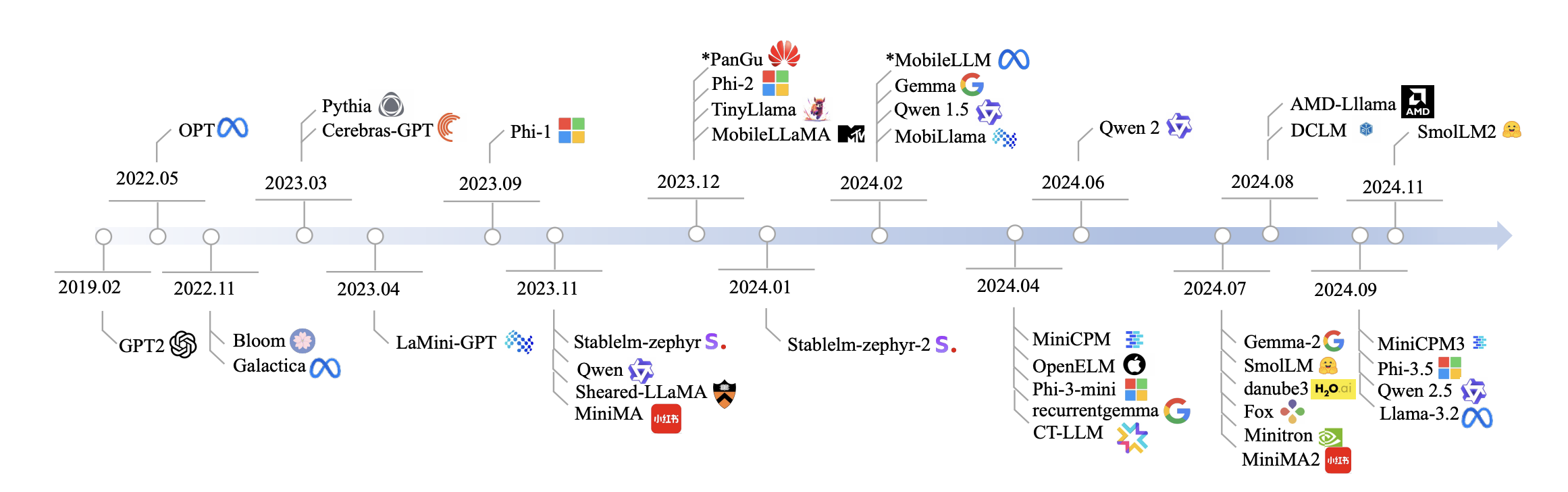
The small language model movement has accelerated dramatically, with 2024-2025 representing a watershed moment. Several breakthroughs have fundamentally changed the calculus on model efficiency:
DeepSeek R1 (January 2025): The Chinese lab demonstrated that reasoning capabilities can emerge through pure reinforcement learning, matching OpenAI o1 performance on math and coding benchmarks while training on constrained hardware (2,000 H800 GPUs vs. 16,000+ H100s for comparable U.S. models). The open-source release under MIT license validated that frontier capabilities no longer require frontier compute. DeepSeek's distilled models (7B-70B) set new benchmarks for their size classes.
Microsoft Phi-4 Series (December 2024 - May 2025): Phi-4 (14B parameters) outperformed GPT-4o-mini across MMLU, GPQA, and MATH benchmarks, proving that synthetic data curation and architectural innovation could compress frontier capabilities into deployable packages. The Phi-4-reasoning models released in 2025 achieve performance better than the full DeepSeek R1 (671B parameters) on AIME 2025, while running on NPUs in Copilot+ PCs.
Meta Llama 3.2 (September 2024): Meta's release of 1B and 3B text models optimized for edge devices, alongside 11B and 90B vision models, created the first production-ready on-device LLM family from a major lab. Quantized versions achieve 56% size reduction with 2-4x inference speedup, enabling smartphone deployment. Day-one optimization for Qualcomm, MediaTek, and Arm hardware established the on-device ecosystem.
Google Gemini Nano (2024): Google's system-level on-device LLM, integrated into Android's AICore service, demonstrated that platform providers would embed SLMs as infrastructure. Gemini Nano handles summarization, rewriting, and security tasks (scam detection in Chrome) entirely offline, with sub-100ms latency on Pixel devices.
Alibaba Qwen 3 Series (2025): The Qwen family expanded to eight models (0.6B to 235B), with SLMs featuring hybrid reasoning capabilities, 100+ language support, and Apache 2.0 licensing. Qwen's aggressive open-source strategy accelerated ecosystem development.
The common thread across these milestones: data quality, distillation, and architectural efficiency matter more than raw scale. This creates investment opportunities in companies that can operationalize these techniques for enterprise deployment.
Thesis 1
Workflow-Embedded Applications with Proprietary Data Flywheels
The strongest applications don't merely deploy SLMs—they own interaction context. Proprietary data creates a compounding flywheel, not just a static moat. While distillation techniques are commoditized through open-source tools, exclusive access to domain-specific data creates durable defensibility—particularly when that data compounds through continuous deployment.
Applications Enabled by SLMs
The Math and Reasoning Gap
While SLMs have made remarkable progress on commonsense reasoning and domain-specific tasks, a persistent capability gap remains in mathematical reasoning and complex logical analysis. The SLM survey found that from 2022-2024, model performance improved by 10.4% on commonsense reasoning but the gap with frontier models "remains significant in tasks requiring complex reasoning or logic, particularly in mathematics." This gap is attributed to the lack of high-quality open-source reasoning datasets.
This creates a structural opportunity for verticalized SLMs. Generic small models struggle with multi-step reasoning, but domain-specific fine-tuning on vertical data—where reasoning patterns are constrained and well-defined—can close this gap. A clinical decision support model doesn't need to solve arbitrary math problems; it needs to reason through diagnostic pathways that follow established medical logic. A legal analysis model doesn't need general theorem-proving; it needs to trace precedent chains within a defined corpus. The reasoning gap in generalist models is precisely where vertical specialization has the most headroom for differentiation.
Healthcare
Clinical documentation represents the clearest SLM success story. Abridge converts doctor-patient conversations into structured clinical notes in real-time, deployed across 150+ health systems including Mayo Clinic, Yale New Haven, and Johns Hopkins. The company's proprietary dataset of 1.5M+ medical encounters creates an insurmountable data advantage. Competitors Nabla and Ambience Healthcare are similarly embedded in clinical workflows, capturing interaction data that cannot be replicated.
Legal
Harvey has become the dominant legal AI platform, serving the majority of top 10 U.S. law firms and corporate legal departments at KKR and PwC. Harvey's value derives from embedding in lawyer workflows and accessing privileged legal work product that competitors cannot replicate. The legal AI market is bifurcating: Harvey for elite firms, EvenUp for plaintiff/personal injury, Casetext for legal research.
Financial Services
Fraud detection learning institution-specific transaction patterns, credit risk models with proprietary customer histories, and compliance monitoring represent core SLM use cases. The data sensitivity of financial services makes local deployment essential—institutions will not send transaction patterns to third-party APIs.
Industrial & Robotics
Quality control on factory floors without internet dependency, predictive maintenance learning equipment-specific failure patterns, and process optimization with proprietary sensor data require SLMs that run at the edge. Companies like Covariant, Bright Machines, and Shield AI are building proprietary data moats through deployment.
Thesis 2
Enterprise Packaging Captures Value Beyond Algorithms
There is significant value derived from making models production-ready for enterprises and maintaining them over time. This follows the Linux vs. Red Hat pattern: the kernel is free, but packaging it with enterprise support, security updates, compliance certifications, and infrastructure integration built a multi-billion-dollar business.
Enterprise Requirements
Enterprises will not deploy open-source distillation scripts directly. The gap between technical capability and production readiness includes:
- Compliance Infrastructure: SOC2, HIPAA, ISO certifications; audit trails; data lineage tracking; access controls
- Integration Requirements: SSO; security monitoring (Splunk, Datadog); model registries; CI/CD pipelines
- Operational Necessities: SLAs with guaranteed uptime; support contracts; rollback capabilities; A/B testing
Open-source tools provide 80% of technical capability but 0% of enterprise requirements. Companies capture value by solving the painful 20%.
Privacy and Edge Deployment as Structural Differentiator
For regulated industries, on-device and on-premise deployment isn't a feature preference—it's a structural requirement driven by compliance, data sovereignty, and liability concerns. Healthcare organizations face HIPAA constraints on patient data transmission. Financial institutions operate under data residency requirements. Legal departments cannot risk privileged work product traversing third-party infrastructure.
These constraints create structural demand for SLM providers who solve the full deployment stack. Google's Gboard demonstrated planetary-scale federated learning with 10-20% accuracy improvements while maintaining differential privacy guarantees—but enterprises cannot replicate this infrastructure internally. Our hackathon highlighted that data sanitization for edge deployment is a genuine pain point without mature solutions.
On-Device Personalization as Enterprise Requirement
Enterprises increasingly require models that learn from user and customer data without sending it to the cloud—a capability they will pay for, not build themselves. The technical challenge is substantial: fine-tuning even a 1.3B-parameter model with LoRA typically requires over dozens of gigs of GPU memory, exceeding the 4-12 GB available on most mobile devices.
Research in 2025 has produced promising solutions that SLM providers can operationalize. Fed MobiLLM (August 2025) introduced server-assisted side-tuning that decouples gradient computation from mobile devices: each device runs only forward propagation and uploads activations, while a server handles backpropagation asynchronously, achieving significantly faster convergence than prior approaches. PF2LoRA, presented at ICLR 2025, proposed two-level LoRA adaptation where a first level learns a common adapter across all clients while a second level enables individual personalization with minimal additional memory overhead.
These techniques remain research-stage, but enterprises are already expressing demand. Financial institutions want fraud models that learn institution-specific transaction patterns. Healthcare systems want clinical assistants that adapt to individual physician documentation styles. Consumer applications want personalization without centralizing user data.
Thesis 3
Hardware-Architecture Co-Design Creates Durable Differentiation
SLM performance isn't just about the weights—it's about how architecture choices interact with specific hardware. The comprehensive SLM survey found that models with similar parameter counts can have dramatically different runtime performance: Qwen1.5-0.5B has more parameters than Qwen2-0.5B but runs 32% faster on the same hardware. Companies that master architecture-hardware co-design have defensible advantages that pure algorithm players cannot replicate.
Architecture Trends Define Deployment Viability
The SLM landscape has converged on specific architectural choices optimized for edge deployment. From 2022-2024, the survey documented clear transitions: Multi-Head Attention (MHA) gave way to Group-Query Attention (GQA), which reduces KV-cache memory requirements. Standard feed-forward networks were replaced by Gated FFN with SiLU activation, which NPUs handle more efficiently. LayerNorm transitioned to RMSNorm for computational simplicity. Vocabulary sizes expanded beyond 50K tokens to improve multilingual capability—but this creates memory tradeoffs, as Bloom's 250K vocabulary causes 3.5x larger compute buffers than OpenELM's 32K vocabulary.
These aren't arbitrary choices—they reflect hardware constraints. GQA reduces memory bandwidth requirements critical for memory-bound edge inference. SiLU activation aligns with NPU instruction sets. The architectural decisions made during pre-training constrain deployment options permanently; a model architected for cloud GPUs cannot be efficiently deployed to mobile NPUs through post-hoc optimization alone.
Quantization Is Not One-Size-Fits-All
The survey's runtime benchmarks revealed that 4-bit quantization hits a sweet spot—but not because lower precision is always better. This finding has investment implications: companies offering "quantization as a service" without hardware-specific optimization provide commodity value. Defensible positions come from deep integration with specific silicon—understanding which quantization schemes a Qualcomm Hexagon NPU handles natively versus which require costly software emulation.
Hardware Is Catching Up to SLM Requirements
Silicon vendors are now designing specifically for SLM workloads. Google's Coral NPU (2025) is an AI-first architecture co-designed with DeepMind, collaborating with the Gemma team to optimize for small transformer models—positioning it as the first open, standards-based NPU designed for LLMs on wearables. MediaTek's Dimensity 9400+ NPU supports speculative decoding natively, handles DeepSeek-R1-Distill models with 1.5-bit to 8-bit precision, and implements Mixture-of-Experts and Multi-Head Latent Attention in silicon.
Qualcomm's Hexagon NPU evolution—fusing scalar, vector, and tensor accelerators with dedicated power delivery—demonstrates that mobile silicon is becoming SLM-aware.
Inference Scaling Laws Change the Calculus
Emerging research on inference scaling laws suggests that the optimal deployment strategy may not be "use the largest model that fits." Work published at ICLR 2025 demonstrated that using a smaller model and generating more tokens often outperforms using a larger model at fixed compute budget.
The "Densing Law" published in Nature Machine Intelligence (November 2025) found that capability density—capability per parameter—doubles approximately every 3.5 months. This means equivalent model performance can be achieved with exponentially fewer parameters over time, but only if deployment infrastructure can exploit this efficiency through techniques like test-time compute scaling, speculative decoding, and adaptive inference.
Companies building hardware-aware optimization layers—architecture search for specific deployment targets, quantization-aware training pipelines, NPU-specific kernel optimization—capture this value.
Thesis 4
Orchestration and Edge-Cloud Collaboration as Control Plane
The future isn't SLM or LLM—it's intelligent routing between them. The capability gap between edge-deployed SLMs and cloud-hosted frontier models will persist; SLMs will not match GPT-5 or Claude 4 on general reasoning. But most queries don't require frontier capabilities.
Why Serving Commoditizes But Routing Doesn't
Raw inference serving has commoditized through open source. vLLM introduced PagedAttention for memory management, doubling throughput for long sequences—it now serves as the de facto backend for most deployments. SGLang optimizes for structured generation. llama.cpp enables inference on consumer hardware. These tools are free, improving rapidly, and increasingly interchangeable.
But serving solves only single-device inference. Harder problems remain unsolved by open source:
- Query classification: Determining in real-time whether a query requires edge SLM, cloud SLM, or frontier LLM capabilities—before incurring inference cost
- Speculative coordination: Managing draft-verify loops between edge and cloud models efficiently across network boundaries
- Fleet synchronization: Updating models across thousands of devices without downtime, version conflicts, or distribution drift
- Cost-quality optimization: Dynamically trading off response quality against latency and compute cost based on application requirements
The Edge-Cloud Collaboration Taxonomy
Research in 2025 has formalized how SLMs and LLMs can collaborate. A comprehensive survey (July 2025) categorized approaches into three patterns:
Cascade Routing: A lightweight router—often a small classifier or uncertainty estimator—determines whether to process a query entirely on edge SLM or escalate to cloud LLM. Blended cost drops 4x+ compared to cloud-only deployment.
Speculative Decoding: The edge SLM rapidly generates draft tokens that a cloud LLM verifies in bulk, accepting correct tokens and correcting errors. This preserves the output distribution of the stronger model while amortizing its cost across multiple tokens per verification call.
Mixture-Based Collaboration: Hybrid approaches that combine assignment and division—using SLM outputs to guide LLM generation, or routing different parts of a complex query to different models based on subtask requirements.
2025 Research Breakthroughs
Several technical advances have made edge-cloud collaboration practical:
Distributed Split Speculative Decoding (DSSD), presented at ICML 2025, partitions the verification phase between device and edge server. This replaces uplink transmission of full vocabulary distributions with a single downlink transmission—significantly reducing communication latency while maintaining inference quality.
Quantize-Sample-and-Verify (October 2025) introduced adaptive mechanisms that dynamically adjust draft token length and quantization precision based on semantic uncertainty and channel conditions. This enables speculative decoding over wireless networks with variable bandwidth.
Uncertainty-aware hybrid inference uses lightweight signals—epistemic uncertainty from temperature perturbations, token importance from attention statistics—to decide which tokens require cloud verification. Tokens are uploaded only when both uncertain and important, reducing unnecessary LLM queries by filtering confident predictions locally.
The Capability Gap Is Structural
These collaboration patterns exist because the SLM-LLM capability gap is structural, not temporary. Frontier models will continue advancing; SLMs will always trail on general reasoning. But this is feature, not bug, for orchestration infrastructure: the gap creates permanent demand for intelligent routing.
Google's Gboard and SwiftKey already implement this pattern—local SLMs handle speech recognition and text prediction, escalating to cloud only for complex understanding. Industrial monitoring systems use edge SLMs for real-time anomaly detection, escalating to cloud LLMs only when potential risks are detected. These deployments validate that hybrid architectures work at scale.
Field Notes: AGI House x AWS SLM Hackathon
On November 8, 2025, we co-hosted an SLM Build Day with AWS in New York City. The event brought together builders, researchers, and engineers to work directly with AWS Trainium chips and explore model optimization, fine-tuning workflows, and reasoning with small language models. In under 8 hours, teams built and demoed functional SLM prototypes capable of real-time reasoning—validating our thesis in practice.
What We Observed
Healthcare applications dominated: Multiple teams built clinical documentation and medical AI tools, including systems for mental health practitioners, multi-agent clinical safety analysis, FHIR-compliant data conversion, and FDA drug label processing.
Agentic architectures emerged: Teams demonstrated scaling embodied AI from single agents to multi-agent systems using SLMs for real-time spatial reasoning—achieving significant cost reductions over cloud-based approaches. This validates the hybrid routing thesis.
Trainium proved production-ready: Teams successfully fine-tuned Qwen models on Trainium, deployed inference endpoints, and achieved real-time performance. Migration tooling projects addressed genuine pain points in the ecosystem.
Privacy-first design is non-negotiable: Projects for sensitive data sanitization and offline-capable systems highlighted that data privacy isn't a feature—it's a fundamental requirement for enterprise deployment.
Implications for Investment
The hackathon reinforced three investment implications: (1) vertical healthcare AI has massive demand and clear willingness to pay; (2) infrastructure for fine-tuning and deploying SLMs on specialized hardware (Trainium, edge devices) is underbuilt; (3) tooling for multi-agent orchestration and hybrid routing remains nascent but clearly needed.
Emerging Opportunities
- Fleet management systems: Orchestrating thousands of edge devices as unified infrastructure
- Confidence-aware routing: Integrating evaluation signals into deployment decisions
- 'Model appliances': Bundling optimized weights with compliance enforcement for regulated verticals
- Outcome-based pricing: Tied to domain KPIs (contracts reviewed, diagnoses confirmed)
- Personal memory stores: Privacy-preserving, persistent context learning individual preferences
Conclusion
The SLM market is bifurcating: frontier APIs win generic tasks, while specialized SLMs win domain-specific applications where structural constraints favor local deployment. We are investing in companies that demonstrate strength across our four theses:
- Proprietary data flywheels in regulated verticals: Companies with exclusive access to high-quality domain data that compounds through deployment, amplified by synthetic data generation techniques.
- Enterprise packaging that solves the painful 20%: Platforms that deliver compliance, integration, on-device personalization, and privacy-preserving deployment—not just fine-tuned weights.
- Hardware-architecture co-design expertise: Teams that understand how architectural choices (GQA, quantization schemes, vocabulary size) interact with specific silicon targets, and can exploit inference scaling laws.
- Orchestration infrastructure for edge-cloud collaboration: Control planes that intelligently route between SLMs and LLMs, manage speculative decoding across network boundaries, and optimize cost-quality tradeoffs dynamically.
The evidence from DeepSeek, Phi-4, Llama 3.2, academic research on inference scaling, and our hackathon participants is clear: efficient, specialized models will power the next generation of AI applications. The opportunity is substantial—tens of billions in addressable market for model development and deployment infrastructure. We're actively seeking founders building in this space.
Acknowledgments
We're grateful to AWS for sponsoring the Small Language Model Build Day and making this research possible. Their commitment to democratizing AI infrastructure—from Trainium chips to the Neuron SDK—enabled participants to build production-grade prototypes in a single day.
Thank you as well to Smart Design, our co-sponsor, for providing venue and operational help. Without the Smart Design team, the hackathon would not have been possible. Additionally, special thanks to Coco Xia and Preethika Pavirala for their invaluable help in organizing and executing the event.
Our judges brought deep expertise across the AI stack, representing organizations including AWS, B Capital Group, Tectonic Ventures, MIT Media Lab, Arcee AI, Smart Design, AGI House Ventures, and Anthropic. The event also featured insightful talks from engineers and researchers at AWS, Hugging Face, Haize Labs, and Arcee AI covering topics from infrastructure optimization to model safety.
Finally, we extend our deepest gratitude to the entire AGI House community for creating a space where ambitious ideas meet execution. This hackathon brought together builders, researchers, and engineers who dedicated their day to pushing the boundaries of what small language models can do—from clinical documentation systems to embodied AI agents to privacy-preserving data tools. The energy, creativity, and technical depth demonstrated by every team validated our belief that the future of AI isn't just about scale; it's about efficiency, specialization, and putting capable models in the hands of builders everywhere. Events like this don't just test technologies; they forge the communities and collaborations that will define the next era of intelligent systems.

