

AGI House is excited to be working with the Google DeepMind team to host the Google Deepmind Build Day. The DeepMind team is bringing Gemini credits and a roster of in-person experts to help builders try the new tools and products coming out of I/O 2026 — and there's a lot worth trying.
I/O 2026 was a notable moment for builders. Several layers of Google's internal AI stack that previously sat behind closed APIs are now hostable, callable, or open-sourced. The same Antigravity harness driving Google's own products is available via SDK or as a hosted Managed Agents API. The Science Skills integration layer — the same code DeepMind's science team uses to query 30+ life-science databases — is on GitHub under Apache 2.0. Gemini 3.5 Flash brings frontier-grade reasoning at speeds that make iterative agent loops economically tractable in a way they haven't quite been before.
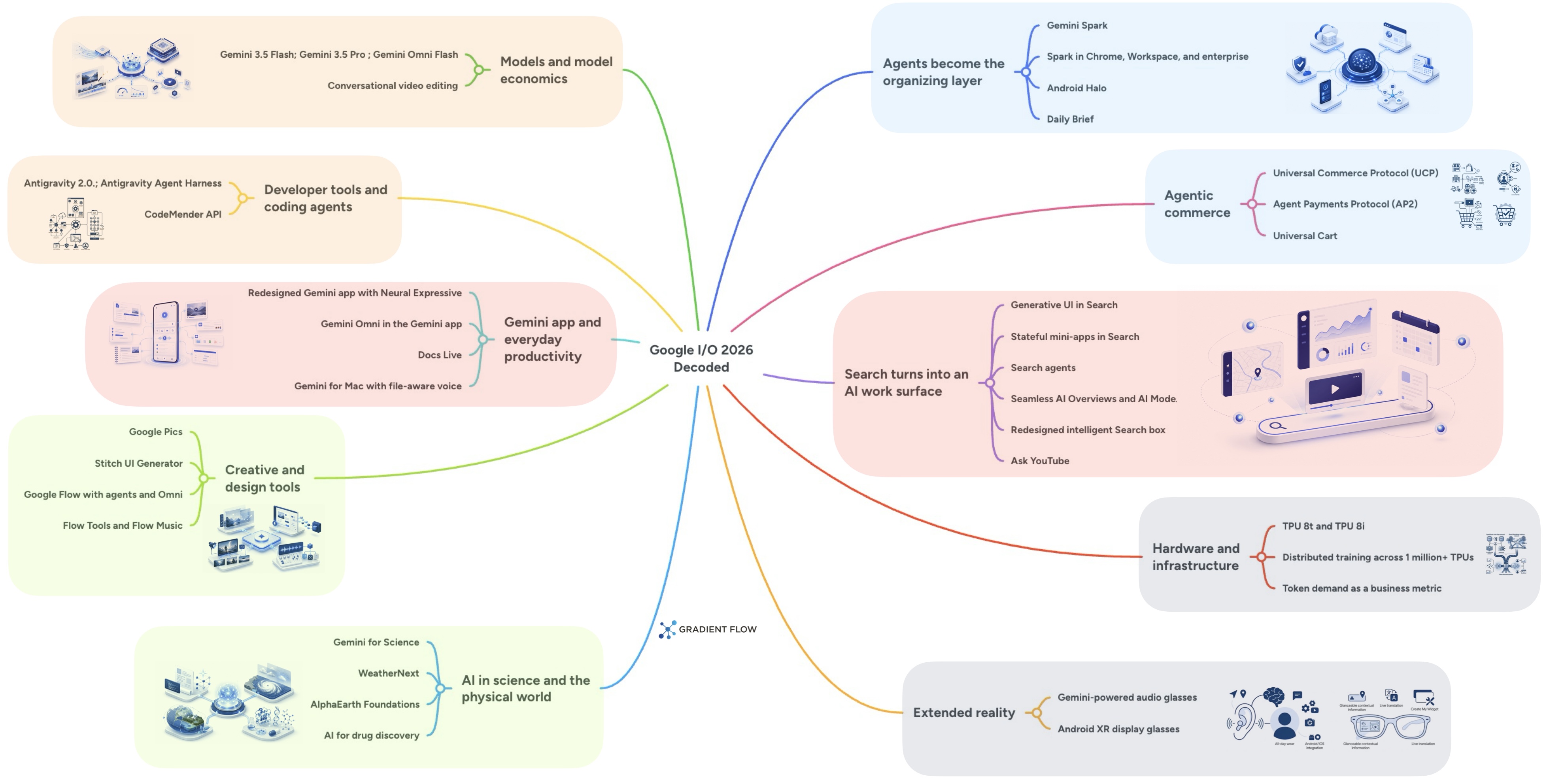
And alongside the platform releases, DeepMind published two of its most ambitious science systems — Co-Scientist and ERA — in Nature the same morning, signaling that AI for science is moving past benchmark-driven claims toward peer-reviewed methodology held to the same standard as conventional science. The three build day tracks correspond to where the most interesting projects live given what's now accessible.
What I/O 2026 opens up for builders
Each track maps to a distinct slice of what's newly possible.
- Track 1 — Agentic Coding & Builder Tools. Build with Gemini 3.5 Flash (GA), Antigravity 2.0 (GA — now a four-piece ecosystem of desktop, IDE, CLI, and SDK, oriented around agent orchestration rather than pair programming), and Managed Agents in the Gemini API (Preview), which exposes the Antigravity harness as a hosted API with single-call agent spin-up in isolated Linux sandboxes and agents/skills defined in versioned markdown.
- Track 2 — Multimodal Agents & Creator Tools. Build with Gemini Omni Flash, the first model in the Omni family, which takes image, audio, video, and text as input and supports conversational video editing (currently GA in Gemini app, Google Flow, and YouTube Shorts; developer API rolling out in the coming weeks). Pair it with Nano Banana for stills, the Live API for real-time multimodal interaction, and Lyria 3 for music — all GA via API.
- Track 3 — AI for Science. Build with Science Skills (GA, Apache 2.0 — integrations with UniProt, AlphaFold DB, AlphaGenome, InterPro, ClinVar, OpenAlex, and ~24 more), the Antigravity harness, and the Managed Agents API. The headline Gemini for Science tools — Hypothesis Generation, Computational Discovery, Literature Insights — are in gradual Labs rollout; their underlying Co-Scientist and ERA systems are the Nature papers above, and their patterns can be approximated with the open primitives.
It's worth pausing on the connective tissue across the tracks before diving in. Google's internal AI work spans a remarkably full stack — TPU 8t/8i at the silicon layer (announced at Cloud Next in April), the Gemini model family, the Antigravity harness for agent orchestration, Google Cloud and the Gemini Enterprise Agent Platform for hosted runtime and governance, and product surfaces from Search to YouTube to Workspace where these are deployed at scale.
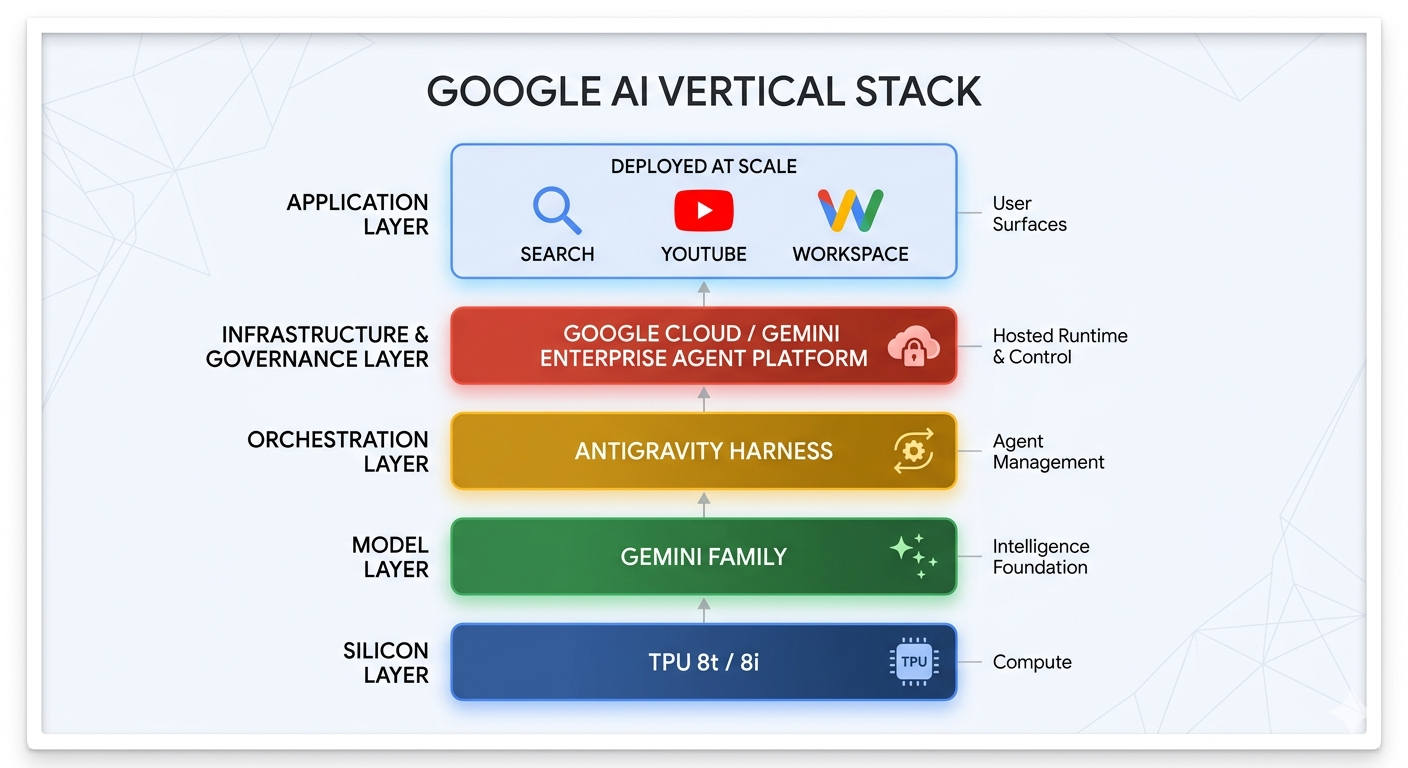
The I/O 2026 launches selectively expose more of those layers — the harness, the agent runtime, the integrated dev surface — to outside builders for the first time. The three tracks are different angles on the same stack, and one of the more interesting things about this build day is that builders are working with the same primitives as Google's own teams.
A few patterns also recur across the tracks and are worth keeping in mind as you pick a project. Skills as a composition primitive — markdown files describing a capability — show up in agentic coding (custom SKILL.md files in Antigravity and the Managed Agents API) and in science (the 30+ skills in the Science Skills bundle). Multi-agent orchestration is visible in Antigravity 2.0's dynamic subagents (Track 1), in Co-Scientist's idea tournament (Track 3), and in creator-tool pipelines that chain text + image + audio + assembly (Track 2). Propose / execute / verify / iterate loops — first explored in FunSearch and scaled in AlphaEvolve — underwrite a lot of the interesting work across both coding and science. The cross-cutting section at the end comes back to these in more detail.
Earlier AGI House x DeepMind memos on coding agents, multimodality, and agent sandboxes cover the foundational primitives. The track sections below assume that foundation and focus on the delta from I/O 2026.
Track 1 — Agentic Coding & Builder Tools
How we got here
Agentic coding has matured into a distinct category of AI work over the past three years, and the I/O 2026 launches sit downstream of a fairly legible research arc.
The story starts with AlphaCode (Li et al., Science 2022) and AlphaCode 2 (DeepMind, 2023), which established that with enough samples and good evaluation, language models could solve competitive-programming problems at human-expert levels. AlphaCode 2 doubled the solve rate of the original using Gemini.

Architectural advancements pushed the field forward. ReAct (Yao et al., 2022) established the template still underlying most production agent harnesses, including Antigravity's: interleave reasoning steps with tool calls, observe results, repeat. Reflexion (Shinn et al., 2023) added verbal self-reflection — when a trajectory fails, the agent explains why and uses that explanation to revise its next attempt.
The benchmark that anchored the next phase was SWE-bench (Jimenez et al., ICLR 2024) and its successor SWE-bench Verified, which moved evaluation from "can the model write code" to "can the model close a real GitHub issue end-to-end."
The most recent inflection came from DeepMind's work on evolutionary code agents. FunSearch (Romera-Paredes et al., Nature 2024) showed that evolutionary search over LLM-generated code could produce verifiably new mathematics — improving bounds on the cap set problem and online bin packing, both decades-old open problems. AlphaEvolve (Novikov et al., 2025) scaled this to whole codebases. Inside Google, AlphaEvolve has been used to optimize data center scheduling, AI training pipelines, and matrix multiplication (it broke a 56-year record on rank-48 tensor decomposition).

Externally, AlphaEvolve hasbeen licensed to BASF and Klarna. The technical paper and the recent one-year impact report are the two most useful reads for understanding what becomes possible when you orient an agent around a strong verifier.
The I/O 2026 launches productize the trajectory of this lineage: Antigravity 2.0 is the harness, Managed Agents is the harness as a hosted API, and Gemini 3.5 Flash is the model engineered to live inside the iterative loop.
What's new in the stack
Three launches anchor the Track 1 stack: Gemini 3.5 Flash, Antigravity 2.0, and Managed Agents in the Gemini API. They're designed to compose, and most of the project ideas below use two or three of them together. A couple of supporting pieces — AI Studio updates and broader MCP support — round out the surface.
- Gemini 3.5 Flash (GA). Frontier-grade reasoning at Flash-series latency. Google's headline claim is roughly 4x the throughput of comparable frontier models, with quality exceeding Gemini 3.1 Pro on most published benchmarks. The practical effect for builders is that a frontier-quality model can now live inside an iterative agent loop without the cost or latency tax that previously made that impractical. Available through the Gemini API, AI Studio, Antigravity, Android Studio, and the Gemini app; thinking-on by default.
- Antigravity 2.0 (GA). Google's coding-agent platform, now packaged as a four-piece ecosystem around a single harness. The desktop "Manager" is the main surface — built around orchestrating multiple agents in parallel with dynamic subagents, scheduled tasks, and integrations into AI Studio, Firebase, Android, and Workspace. The original Antigravity IDE (the VS Code–style surface from late 2025) is still around for hands-on coding work. The Antigravity CLI is the terminal-first interface — Gemini CLI users have until June 18 to migrate. The Antigravity SDK (Python) exposes the same harness for self-hosting. The conceptual shift worth noticing: Antigravity 2.0 is built around the assumption that you're coordinating agents in parallel, not editing alongside one.
- Managed Agents in the Gemini API (Preview). The Antigravity harness as a hosted API. A single call to the Interactions API provisions an isolated Linux sandbox with the agent (running Gemini 3.5 Flash) ready to reason, run code, manage files, and browse the web. Sessions are resumable across calls. Custom agents and skills are defined as versioned markdown files (AGENTS.md and SKILL.md). Deep Research — launched in December 2025 as the first managed agent — is the cleanest reference example.
Two supporting pieces worth knowing about:
- AI Studio updates (GA). Native Kotlin vibe-coding for Android with direct Play Console publishing, Workspace API integration, one-click Cloud Run deployment with Firebase services, Export-to-Antigravity, and an AI Studio mobile app for capturing ideas on the go.
- MCP support across the ecosystem. Antigravity 2.0, the CLI, the SDK, and Managed Agents now share one MCP config location, which is a useful cleanup over the prior split. MCP servers from Composio, Smithery, Stripe, Linear, Notion, Slack, Shopify, and others wire in with one config. WebMCP is in experimental origin trial in Chrome 149 — forward-looking but not stable to build on yet.
Potential project ideas
A spread of ideas of varying difficulty.
- A skill pack for a domain you actually know. Pick something narrow — log triage for a specific stack, code review against a specific style guide, a migration assistant for a particular framework version, an oncall runbook executor. Author 3–5
SKILL.mdfiles, register them with a Managed Agent, demo on representative tasks. Tractable on the day; extends naturally into a real internal tool. - An MCP server for an internal tool, plus an agent that uses it. Pick a tool you actually use — CI, observability, secrets management, an internal API — and build an MCP server exposing 4–6 operations on it. Then build a Managed Agent that uses it via natural-language tasks. The demo is the end-to-end loop. MCP is the standardization play; this project makes that standardization concrete.
- A scheduled background agent against a real source. Use Antigravity 2.0's scheduled-tasks feature to run an agent against your inbox, a GitHub repo, a Notion DB, or a Slack channel on a cron-like cadence. The demo is "I left this running for two hours; here's what it flagged, and here's where it would have escalated to me."
- A multi-agent code refactor with explicit verifiers. Subagent A proposes a refactor (extract a service from a monolith, migrate a test suite to a new framework, port a module to a new type system). Subagent B runs the test suite as the verifier. Subagent C reports diffs and rationale. The most interesting demo is the failure path — the verifier rejecting twice and the proposer adapting on the third try.
- A verifier-first agent on an open algorithmic problem. Pick a Kaggle micro-challenge or a constrained optimization problem with a clean scoring function. Write the verifier first — this is the hard part — then point a Managed Agent at it with AlphaEvolve-style propose/score/iterate. Demo: "we ran N candidate solutions and the best one scored X." A stripped-down AlphaEvolve in a day. References: the AlphaEvolve paper, the impact post, and the public results repo.
- An eval-driven self-improving agent loop. Pick a tractable target — prompt optimization for a downstream task, test-coverage maximization on a small repo, latency reduction on a single code path. The agent generates candidate improvements, runs them through an eval harness, scores the results, and feeds the scores back into the next round. Different from #5 in that the verifier is an evaluator over real-world behavior (test pass rate, latency, output quality) rather than a clean correctness check. Demo: improvement curves over N iterations, with the agent's reasoning visible between rounds. This is the same propose/evaluate/iterate shape AlphaEvolve has been applied to internally at Google for data center scheduling and training pipeline optimization — scaled down to something a single builder can stand up in a day.
- A long-horizon code migration agent. Take a non-trivial real codebase and migrate it to a target stack (Python 2 → 3, Angular → React, Java → Kotlin) using Antigravity subagents to decompose by module. Demo: passing tests on a substantial diff. Hard; many builders won't fully finish; the partial product is interesting and what gets shown matters.
- A prompt-to-Android pipeline with a real release loop. Use AI Studio's native Kotlin support + Play Console publishing to go from idea → working Android app → published to a test track in one sitting. Demo is the full loop, end-to-end.
- Antigravity SDK embedded in a non-Google surface. Put the SDK inside a JetBrains plugin, a GitHub Action, or a CircleCI runner. End-of-day demo: a single PR being reviewed by the agent in CI on a real repo.
Track 2 — Multimodal Agents & Creator Tools
How we got here
Multimodality has been a steady research direction for DeepMind since well before Gemini, and the I/O 2026 launches are best understood as the latest layer in a long stack of work.
The understanding side traces back to Flamingo (Alayrac et al., NeurIPS 2022) — the visual-language model that established interleaved image-text reasoning at scale. The Gemini 1.0 Technical Report (DeepMind, 2023) was the next inflection: rather than retrofitting modalities onto a text model, Gemini was trained as native multimodal from the start.

On the generation side, DeepMind's Veo line (2024–2025) became the cinematic video generation model — strong on camera control, and the first frontier video model with reliable native audio. Veo 3.1 (October 2025) is still the right tool for longer-form, higher-fidelity video and powers parts of Google Flow.
The agent prototype that previewed what's now shipping is Project Astra (DeepMind, demoed at I/O 2024) — a real-time multimodal assistant that could see, listen, talk, and remember across a session. For interactive worlds, Genie (DeepMind, ICML 2024) and Genie 3 (research preview, 2025) generate playable game-like environments from images or text. The recent Project Genie + Street View integration (announced at I/O 2026) makes this category newly relevant for any "explore-a-place" project, though there's no developer API yet.
On provenance: SynthID (DeepMind, 2023) is converging into the watermarking standard across the industry. Google has watermarked roughly 100B images and 60K+ years of audio with it, and adoption by OpenAI, Kakao, and ElevenLabs is consolidating it as a cross-vendor standard alongside C2PA Content Credentials.
For broader context, the field-shaping work outside DeepMind worth being aware of is DiT (Peebles & Xie, 2023) — the diffusion-transformer architecture underpinning most current video models — and OpenAI's Sora technical report. A trend visible across the field: scaling specialized media models appears to be hitting diminishing returns, and the unified-modality direction Omni represents is the field's open bet for the next jump in capability.
What's new in the stack
The headline launch is Gemini Omni Flash, but the rest of the multimodal stack has matured around it into a coherent toolkit.
- Gemini Omni Flash (GA in Gemini app, Google Flow, YouTube Shorts; developer API rolling out in the coming weeks). The first model in the Omni family. It takes image, audio, video, and text as input and generates edited video grounded in Gemini's world knowledge. The differentiator isn't raw generation quality — Seedance, Sora, and Runway lead on specific pure-generation benchmarks — it's conversational editing. Characters, scenes, and physics hold across turns, so "make it night, now add a violinist in the corner, now change the camera angle" works as multi-turn refinement rather than three independent generations. The Omni branding is intentional: rather than calling this "Veo 4," Google is signaling that the next direction is unified models that perceive, reason, and generate across modalities in a single system. Output is currently capped at 10 seconds.
- Note: Omni Flash output is reachable via product surfaces but not yet via developer API, so for programmatic video work please refer to Veo 3.1.
- Nano Banana / Nano Banana 2 (GA via Gemini API). The image generation and editing model. 50B+ images generated to date across versions. The property that matters for iterative work is object-level editability — outputs aren't flat raster, which means conversational editing on stills works cleanly. The lowest-latency creative primitive in the stack.
- Live API (GA since late 2024). Real-time multimodal interaction over WebSockets, currently running on Gemini 2.5 Flash Native Audio. It handles interruptions mid-sentence, ambient audio cues, and continuous video input, with tool use, code execution, and search-as-a-tool available within a single session. The production conduit for anything that needs to feel like a conversation rather than a request-response. The examples repo is the right starting point.
- Lyria 3 (GA via Agent Platform). Music generation, used for the I/O 2026 opening sequence. Fast enough for production creator workflows.
- Veo 3.1 (GA) and Google Flow (GA). Veo 3.1 is the cinematic video model — strong on camera work and reliable native audio. Google Flow is the integrated creative tool built on Veo and adjacent models, with vibe-coded effects, animations, and text layering. Worth knowing about for any project that needs longer-form or higher-fidelity output than Omni Flash currently produces.
- SynthID (GA detector in the Gemini app). Worth surfacing in any creator project as the provenance story.

Potential project ideas
A spread of ideas, varying difficulty. A few practical notes on what's API-accessible during the day: Omni Flash output is reachable via Gemini app and Google Flow but not yet via developer API — for programmatic video, use Veo 3.1. Nano Banana, the Live API, Lyria 3, and Gemini 3.5 Flash are all GA via API. A useful pattern when wiring projects together: Live API for real-time interaction, Nano Banana for stills, Veo 3.1 (or Flow) for video, Lyria 3 for music, and 3.5 Flash to orchestrate.
- A real-time visual assistant via Live API. Stream camera + microphone to Gemini Live and respond with continuous audio. Pick a specific use case — cooking, repair, language learning, museum/exhibit narration. The demo is a single uninterrupted conversation with the camera pointed at something real. Conceptual lineage: Project Astra. The Live API examples repo is the right starting point.
- A creator brief-to-finished-short pipeline. Take a written brief, use Gemini 3.5 Flash to generate a script with shot list, generate visuals with Nano Banana or Veo 3.1, generate music with Lyria 3, assemble into a complete short. End-to-end. Demo is a 15–30 second piece produced live for the audience. Touches all the creator-tool surfaces in one project.
- A conversational image editor on Nano Banana. A chat-driven editor where each turn applies an edit and the next turn refines it ("now make the lighting warmer, now add a person in the background, now change the time of day"). Approximates the Omni Flash conversational pattern on a still-image foundation that's API-accessible today. The interesting part is the state model — keeping the conversation grounded so edit 5 still makes sense given edits 1 through 4.
- A multimodal product configurator. Upload a photo of a space (a room, a desk, a yard). Describe desired changes by voice via Live API. Generate a rendered preview with Nano Banana. Iterate conversationally. The demo is the end-to-end loop and a before/after comparison refined over several turns.
- A live-event recap agent. Ingest a chunk of footage (video + audio), produce highlights, social cuts at three different lengths, a written summary, and thumbnails. The demo is "we ran this on 30 minutes of conference footage; here's what fell out." Touches video understanding (3.5 Flash), audio (Live API), and image generation (Nano Banana).
- A wayfinding assistant for blind and low-vision users. Real-time scene description from camera input via the Live API, integrated with Google Maps directions for turn-by-turn navigation. The agent provides continuous audio guidance and handles natural follow-ups ("which way is the door I just passed?" "is there a curb here?"). Differs from #1 in being purpose-built and safety-critical — committing to a specific user lets the project surface design questions about confidence calibration, latency tolerance, and fallback behavior that general "visual assistant" demos elide. Demo: a single uninterrupted walking session through a real space. Genuinely buildable in a day.
- A Lyria 3–centric creative tool. Build something where music generation is the centerpiece, not a component. A few directions worth picking from: a tempo/mood-driven video cutter that takes user-uploaded clips and edits them to a Lyria-generated soundtrack; a meditation-or-sleep-story generator that produces narration via the Live API, ambient music via Lyria 3, and matching visuals via Nano Banana; an adaptive game soundtrack that responds to in-game state via the Gemini API. Demo: a complete creative artifact where Lyria 3 is doing the heavy lifting. Lyria 3 is GA on the Agent Platform and underused in public creator demos — this is a chance to show what it can do.
- A multimodal "remix" tool, designed to extend past the build day. Once the Omni Flash developer API lands, the highest-leverage project here is a multi-turn conversational video editor where a user uploads existing footage and refines it through chat. The day's version: scaffold the UX, orchestration logic, and state management against the Live API + Nano Banana, with Omni Flash slotted in once the API is available. The conversational-state and orchestration work is the substantive part — and it's all doable on the day.
Track 3 — AI for Science
How we got here
DeepMind's science portfolio is the deepest in any AI lab, and the I/O 2026 announcements sit at the end of a long arc of work that's worth being literate in before picking a project.
The paper that made the field credible was AlphaFold 2 (Jumper et al., Nature 2021) — protein structure prediction at near-experimental accuracy, which essentially turned AI into a legitimate scientific instrument overnight. AlphaFold 3 (Abramson et al., Nature 2024) extended the approach to protein–ligand and protein–DNA/RNA complexes. The AlphaFold Database (now integrated into Science Skills) is widely used across structural biology and is the kind of artifact that turns an AI advance into infrastructure.

The genome side came later. AlphaGenome (DeepMind, 2025) predicts how DNA variants affect gene regulation and expression — its API is one of the Science Skills integrations. On variant pathogenicity, AlphaMissense (Cheng et al., Science 2023) catalogued 71M+ missense variants across the human proteome, classifying 89% of them — useful in clinical genetics.
Outside biology, GraphCast (Lam et al., Science 2023) and its successor WeatherNext (DeepMind, 2026) deliver medium-range weather forecasts more accurate than the ECMWF operational system — Hurricane Melissa's recent landfall forecast (Jamaica) was a public validation moment. GNoME (Merchant et al., Nature 2023) used graph networks to discover 2.2M predicted-stable crystal structures, of which 380K were classified as likely synthesizable — materials discovery at a new scale.
The two papers most worth reading before the build day are the ones published the same morning as the I/O 2026 announcement. Co-Scientist (DeepMind, Nature 2026) is a multi-agent system that generates, debates, and ranks scientific hypotheses through what the paper calls an "idea tournament" — proposer agents put forward hypotheses, critic agents push back, and a ranking head selects the strongest.

ERA (Empirical Research Assistance) (Google Research, Nature 2026) orchestrates the empirical-research workflow itself — notably, ERA outperformed the CDC's COVID-19 hospitalization-forecast ensemble in a head-to-head comparison reported in the paper. These two systems are the methodological blueprints for the headline Gemini for Science tools, and their patterns are what most Track 3 build day projects will end up approximating using the open primitives. AlphaEvolve (covered in more detail in Track 1's reading) is the engine behind the Computational Discovery tool.
What's new in the stack
The buildable surface for Track 3 is more layered than the other two: the headline reference tools are in gradual Labs rollout (not directly callable APIs yet), but the underlying primitives are mostly GA and can be used to approximate the same patterns.
- Science Skills (GA on GitHub, Apache 2.0; integrated with Antigravity). The cleanest piece to anchor on. A bundle of ~30 skills wrapping the major life-science databases and tools — UniProt for protein sequences, the AlphaFold Database for predicted structures, AlphaGenome for variant interpretation, InterPro for protein family classification, ClinVar for clinical variants, OpenAlex for literature, and others. Each skill is a SKILL.md file that works in Antigravity 2.0 locally and via the Managed Agents API.
- Gemini for Science reference tools (Previewed, gradual Labs rollout). Three prototypes worth knowing about even though they're not directly callable on the day: Hypothesis Generation (built on Co-Scientist), Computational Discovery (built on AlphaEvolve and ERA), and Literature Insights (built on NotebookLM). The methodology is in the Nature papers above, which means the patterns can be replicated using Managed Agents and custom skills.
- Managed Agents API (Preview). Same as Track 1, but particularly useful here for projects that approximate multi-agent patterns from Co-Scientist or ERA.
- NotebookLM (GA). Built on Gemini, optimized for grounding in user-supplied document corpora. Underwrites Literature Insights and is directly usable on the day for any project that needs to synthesize across papers.
- Gemini Deep Research and Deep Think (both GA). Useful for projects that need extended-context reasoning over web sources or structured deliberation over hard scientific questions.
- Adjacent infrastructure. MedGemma (medical imaging + text), Earth AI (geospatial), and Earth Engine remain GA and available, relevant for projects that lean into clinical imaging, environmental science, or geospatial work rather than the life-science core.
The conceptual move worth noticing here is that scientific workflows are being framed as a special case of agentic workflows, not as a separate category. The same Antigravity harness running a code refactor in Track 1 runs the protein analysis in Track 3 — only the skills differ. The build day is in part a test of whether that bet (general agents with domain skills outperform specialized scientific models) holds up in practice.
Potential project ideas
A spread of ideas, varying difficulty. A few notes on the toolkit: Science Skills + Managed Agents is the workhorse combination, and most projects will involve approximating one of the reference tools at hackathon scale. Validators and verifiers matter even more in science than in coding — projects that lean on PubMed grounding, citation chains, or actual lab-data benchmarks tend to land much better than projects that don't.
- A protein analysis pipeline using Science Skills. Take a UniProt ID, retrieve sequence and AlphaFold structure data via Science Skills, run structural bioinformatics analysis (binding site prediction, surface analysis), surface candidate disease mechanisms. Demo: "run this on AK2 and reproduce the rare-disease analysis pattern Google showed in the Gemini for Science announcement." End-to-end, demoable, and a direct exercise of the headline Science Skills surface.
- A literature synthesis agent using Managed Agents + NotebookLM. Given a research question, search a curated corpus (OpenAlex via Science Skills, plus user-supplied papers via NotebookLM), build a structured table of findings with citations, identify gaps in the literature. Approximates Literature Insights using primitives that are GA today. Demoable on a specific question ("what's known about KRAS-G12C inhibitor resistance mechanisms?").
- A miniature hypothesis-tournament agent. Approximate Co-Scientist: one agent generating hypotheses, another critiquing on plausibility grounds, a third ranking via a verifier (e.g., agreement with PubMed-grounded evidence). The demo is the tournament running on a real scientific question, with visible round-by-round dynamics. Reference: the Co-Scientist Nature paper.
- A computational discovery loop on a small scientific problem. Pick a problem with a clean verifier — fitting a small molecular property, solving a constrained optimization in a tractable scientific domain. Build an AlphaEvolve-style propose/score/iterate loop using Managed Agents. Demo: best-found candidate after N iterations, with progress curves.
- A materials-discovery verifier loop. Pick a small materials-property optimization — predicting whether a candidate crystal structure is likely to be stable, or optimizing for a target property like bandgap or thermal conductivity using publicly available ML-property estimators (e.g., the Materials Project API, M3GNet, MatBench). Build an AlphaEvolve-style propose/score/iterate loop where the proposer generates candidate structures and the scorer estimates the property. Demo: distribution of candidates explored, best-found result with progress curves. Lineage: GNoME (Merchant et al., Nature 2023) for the materials discovery framing; AlphaEvolve for the loop structure.
- A drug-target interaction predictor. Combine ChEMBL or PubChem chemical data (via custom skill or MCP server) with AlphaFold structures and AlphaGenome variant data via Science Skills. Predict candidate target proteins for a given small molecule, or vice versa. Demo: a small case study comparing predictions to known interactions.
- A MedGemma medical imaging agent. Build an agent that ingests medical imaging (chest X-rays from NIH ChestX-ray14, dermatology images from the ISIC archive, retinal fundus images from EyePACS — all publicly available), uses MedGemma to produce a structured interpretation, and grounds the interpretation with citations to clinical literature via Science Skills. Demo: side-by-side comparison of MedGemma's structured output against published case reports. Lineage: Med-Gemini and MedGemma — both flagged in the Gemini for Science announcement as concrete applications.
- A structural-review assistant for clinical trial protocols. Given a draft trial protocol (publicly available examples on ClinicalTrials.gov work well as source material), run a structural pass against a checklist of common design pitfalls — sample size calculations, control arm appropriateness, inclusion/exclusion specification, endpoint clarity, statistical analysis plan completeness. Output: a structured review with flags and suggestions, not a full redesign. Demo: side-by-side of the original protocol and the flagged issues. The structural-review framing keeps it tractable — open-ended "trial design" is too ambitious for a day, but checklist-grounded review is genuinely useful and demoable.
- A scientific peer-review assistant. Approximate Google's Paper Assistant Tool (PAT) and ScholarPeer from the Gemini for Science announcement: read a paper draft, check claims against cited evidence, flag potential issues, suggest figure improvements. Connects directly to Google's own pilots with ICML, STOC, and NeurIPS.
- A natural-disaster-risk reasoning agent built on WeatherNext output. Combine WeatherNext forecast data with regional vulnerability data from Earth Engine to surface actionable risk assessments. Demo: a specific scenario (e.g., a tropical storm projected to make landfall in N days) with reasoning over data the agent retrieved itself.
Cross-cutting: patterns across tracks
Five patterns recur across the tracks and are worth seeing as connective tissue rather than coincidence.
- Skills as a composition primitive. Markdown files (SKILL.md) describing a capability the agent can use. The same skill works locally in Antigravity, via the Managed Agents API, and inside Antigravity-orchestrated workflows. Track 1 builders will be authoring custom skills; Track 3 builders will be using Science Skills directly. The open question worth thinking about: skills compose well at small scale (the current Science Skills bundle has ~30 skills and behaves well), but there isn't public data yet on the upper bound. Projects that author many skills together — or that compose skills from different domains — will surface interesting failure modes.
- Multi-agent orchestration as the workflow shape. Antigravity 2.0's dynamic subagents (Track 1), Co-Scientist's idea tournament (Track 3), and creator-tool pipelines that chain text + image + audio + assembly (Track 2) share a common shape: multiple specialized agents coordinated by a manager. The A2A protocol v1.0 is the standardization layer when agents need to cross organizational boundaries. For most build day projects, the orchestration logic is straightforward (a Python script wiring Managed Agents calls together); the interesting work is in how subagents are specialized and how the manager handles disagreement and failure.
- Propose / verify / iterate as the dominant loop. Originally explored in FunSearch, scaled in AlphaEvolve, and now visible across the tracks: in code refactoring (Track 1), in scientific hypothesis generation (Track 3), and in creator-tool refinement (Track 2). The pattern that consistently tends to work: front-load the verifier design. A weak verifier wastes any amount of model intelligence; a strong verifier extracts useful signal even from a mediocre proposer.
- MCP and the protocol layer. Worth knowing but not necessarily worth building on as the primary point of a project. MCP is mature; A2A v1.0 is mature; WebMCP is experimental. For Track 1 projects exposing a tool to an agent, an MCP server is the right wrapper. For projects that need agents in different orgs to talk to each other, A2A is the protocol. For projects that need agents to interact with arbitrary web pages, WebMCP is the forward-looking standard, but it's not yet stable enough to anchor a build on.
- The sandbox-to-real-world gap. Across all three tracks, the same caveat applies: agents that run cleanly in sandboxes often don't translate cleanly to real-world deployment. Projects that gesture honestly at this gap — explicit human-in-the-loop checkpoints, dry-run modes before commits, escalation logic when confidence is low — tend to read better both technically and practically than projects that elide it.
And with that said...
Get building! We're looking forward to seeing what you make. Reach out to the AGI House or DeepMind teams ahead of the day if you want help refining a project idea, and bring your sharpest questions for the experts on the floor. See you soon.

