

On Sunday, May 17, around twenty researchers, engineers, and founders gathered at AGI House over brunch for a reading group with Marco Pavone (Stanford professor, NVIDIA's autonomous vehicle research lead), Yan Wang, and Wenjie Luo, both senior researchers on the Alpamayo team. The starting point was the two recent Alpamayo publications — Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail and the Alpamayo Open Platform expansion announcement — alongside two closely related NVIDIA works that came up repeatedly throughout the conversation: Counterfactual VLA and Cosmos-Drive-Dreams.
The discussion covered everything from the architectural specifics of reasoning VLAs to the strategic implications of agentic workflows for team productivity. What follows are eleven takeaways for builders, researchers, and founders who weren't in the room — covering threads worth pulling on whether you're working on autonomous driving, embodied AI, generative simulation, or reasoning models more broadly.


1. The auto-labeling pipeline is the program — and it's about to open up
One throughline of the discussion was where the bulk of the Alpamayo engineering effort actually went:
"A significant fraction of the Alpamayo program was not about developing an architecture itself. It was actually about curating the dataset and building the auto-labeling pipeline."
The Chain of Causation (CoC) framework is presented in the paper as a direct response to three pathologies that pervade prior reasoning datasets in AV: vague behavior descriptions ("be cautious"), superficial reasoning that names contextual factors with no causal weight ("sunny weather," "wide roads"), and causal confusion — referencing future events the model couldn't have observed at inference time. The pipeline encodes structure: closed-set decision taxonomies, open-set causal-factor schemas, composed reasoning traces tying them together.

According to the Alpamayo 1.5 announcement, the CoC autolabeling pipeline itself is being released soon, alongside reasoning labels for the PhysicalAI-AV dataset. For external teams this matters because the data spec — historically the part not broadly available outside large industry labs — is becoming open infrastructure. If you've been building reasoning-VLA systems and felt limited by data quality, worth calibrating your roadmap around the release.
2. Causal locality — and the move toward agentic keyframe selection
A technical principle that came up repeatedly: at training time a labeler can see what happens next; at inference time the model cannot. If you don't engineer that asymmetry away, the model learns to imitate explanations it can never reproduce in deployment.
The Alpamayo answer is keyframe-anchored labeling. Identify the moment a decision is actually made, label "critical components" only from a short pre-decision history window, label the decision itself from the broader segment. The labeling interface enforces the separation rather than relying on annotator discipline. The principle generalizes well beyond AV: any reasoning-from-perception task is vulnerable to information leakage from labelers seeing beyond the inference-time observer's horizon.
Yan flagged that the team is now moving beyond handcrafted scenario rules toward agentic keyframe selection — using agents to find informative training moments at scale, since "handcrafted rules limit the coverage." This sits inside a broader shift the team is making toward agentic workflows for skill development, fine-tuning, evaluation, and scenario generation. As Marco put it: "we can uplift productivity to a point where the upper bound is more about how much compute we have, as opposed to how many people we have on the team." For teams thinking about what reasoning-VLA development will look like in two years, agentic data curation is one of the clearer near-term shifts.
3. Counterfactual VLA: turning reasoning from description into self-reflection
The Counterfactual VLA paper, released by the NVIDIA team late last year, came up several times throughout the discussion. The framing offered: today's chain-of-thought is "the boring way of using reasoning" — a linear, descriptive trace of what the model sees and intends. CF-VLA proposes something different: a self-reflective loop where the model proposes meta-actions, reasons about its own proposal, and revises it before generating the trajectory.
The mechanism is laid out in the paper. The model first emits a sequence of time-segmented meta-actions describing its driving intent. Conditioned on those meta-actions and the visual context, it then asks itself: "If I follow this plan, what would happen — is that desirable?" When the answer is no, it edits the meta-actions before they reach the trajectory decoder. The training signal comes from a rollout–filter–label pipeline that mines the model's own bad rollouts — finding scenes where pre-filling the ground-truth meta-actions would substantially improve the trajectory, i.e., scenes where the bottleneck is decision quality rather than trajectory decoding.

The empirical lift: meaningful reductions in trajectory error and collisions over non-reasoning baselines, concentrated in scenarios that require complex interactive decisions — cut-ins, lane changes, turning maneuvers, VRU interactions. The architectural pattern is what to take away: a language model that critiques its own action inside the same forward pass, without an external verifier or world model. It's a template that may generalize beyond AV.
4. Adaptive reasoning can emerge from data mixing — no router or RL required
"Reasoning on demand" came up as a near-term direction: today the model reasons on every input, but uneventful driving shouldn't pay test-time compute for reasoning it doesn't need. The Alpamayo-R1 paper's future-work section explicitly calls this out as well.
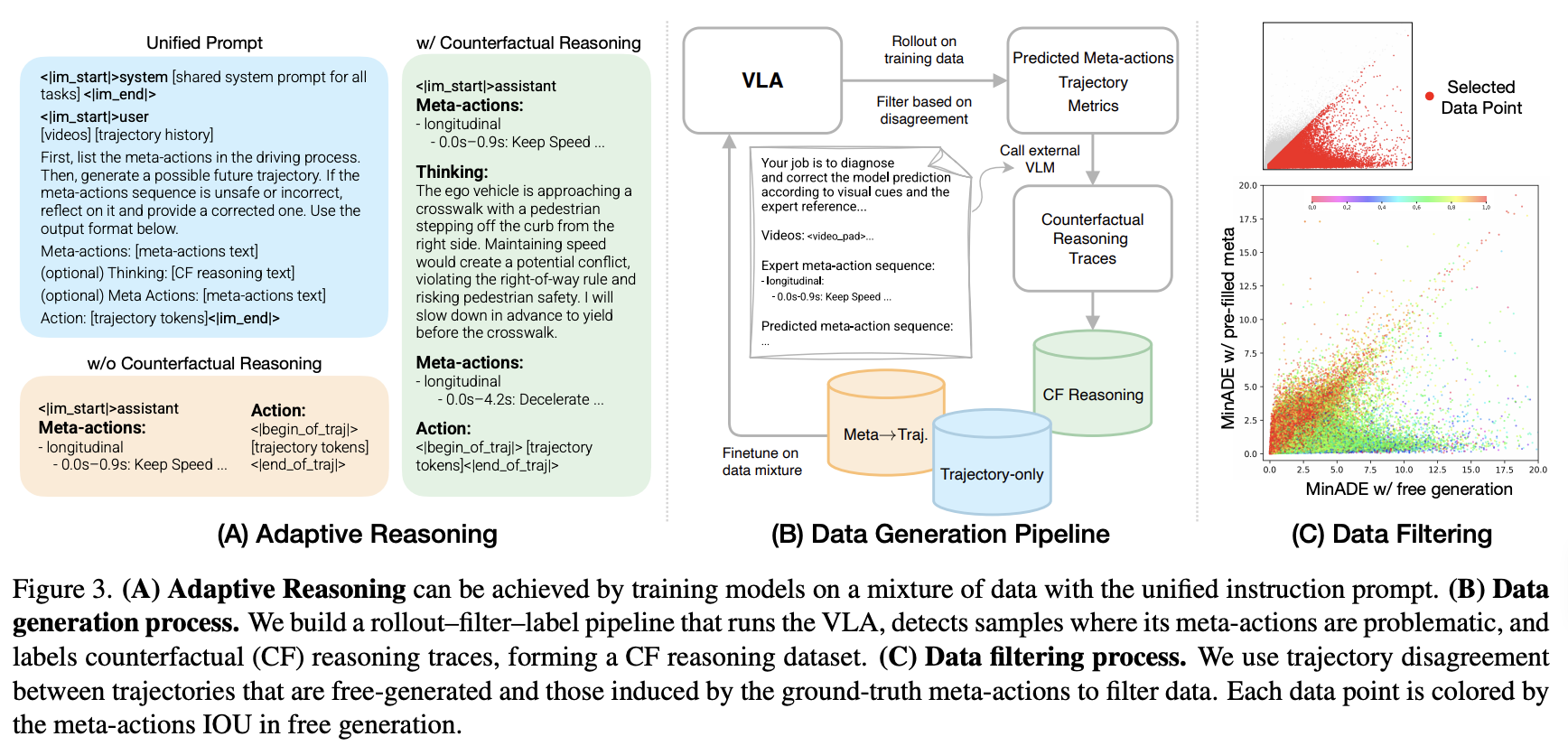
CF-VLA shows that adaptive thinking can emerge from supervised fine-tuning alone — train on a mixture of samples that do and don't contain reasoning traces under a unified prompt, and the model implicitly learns when to emit a thinking block. The pattern is striking: the model thinks more often, and gains more from thinking, in exactly the hard scenarios where reasoning matters most. Force-thinking on every scene actually degrades performance.
This contrasts with prior work (e.g., AdaThinkDrive) that uses reinforcement learning to learn when to think. CF-VLA suggests the simpler recipe — clever data construction under a unified prompt — may be sufficient. The deeper research question shifts from "how do we make reasoning better" to "when should reasoning fire at all," and the answer increasingly looks like one the model can learn for itself.
5. Two kinds of recall — and reasoning as semantic search
A useful conceptual distinction that came out of the Q&A on chain-of-thought interpretability: there are two kinds of recall a driving model needs, and the field tends to conflate them.
- Within-frame recall: covering all the critical actors actually visible in the current scene. Improvable with better perception, larger architectures, more careful supervision over critical components.
- Beyond-frame recall: reasoning about agents that aren't visible — the child possibly behind the parked van near a school, the cyclist about to emerge from an occluded driveway. This is where counterfactual reasoning, hypothesis generation, and "what-if" thinking become essential.
Linear chain-of-thought handles the first poorly and the second barely at all. The framing offered for what comes next: the more interesting form of reasoning is a search in semantic space rather than a description. The model should ask: "What if there's a kid behind that car? What if the lead vehicle brakes hard? What if I'm wrong about the right of way?" Each branch surfaces possibilities the perception system hasn't directly observed — and lets the policy be proactive, adjusting speed near a school before a child runs out, not after.
This is computationally expensive, which is why the team is looking seriously at diffusion models for reasoning — one of their architectural benefits is unrolling multiple reasoning traces in parallel rather than committing to a single linear chain. The shift from CoT-as-monologue to CoT-as-search is one of the more concrete near-term research directions that emerged from the conversation.
6. Reasoning's gains live in the long tail — averages will hide them
A framing point worth internalizing for evaluation infrastructure: on a typical broad evaluation set, reasoning's contribution to driving performance looks modest, because most driving is uneventful straight-line motion. The interesting question is what happens in the tail — intersections, vulnerable road users, construction zones, cut-ins.
Both Alpamayo-R1 and CF-VLA show this pattern empirically: on curated hard sets, the gap between reasoning and non-reasoning models is several times what it is on broad evaluation, and closed-loop simulation in AlpaSim widens it further. Marco put it this way: "If you just evaluate on a very large number of clips, the improvements averaged across the large evaluation set are there, but not that impressive… But on a curated hard set, that's where we really see the big gains."

The implication for the field: aggregate open-loop benchmarks systematically under-credit reasoning models. The discriminating signal increasingly lives in tail-specific evaluation — curated hard sets, behavioral OOD benchmarks (NVIDIA flagged an upcoming PAI-OOD release), and dense-interaction closed-loop scenarios.
7. Edge inference for reasoning models is no longer the bottleneck people fear
A counterpoint to the common assumption that reasoning models can't fit on AV-grade hardware: the techniques to make them run in real time are progressing rapidly, and Alpamayo deploys several in parallel. The toolbox that came up:
- Distillation — the 10B open-weight model is a teacher; what actually runs on the car is distilled down.
- Speculative decoding — the action expert generates many tokens that are then verified by the main model, cutting sequential decoding bottlenecks.
- Hybrid encoders — convolutional + transformer vision encoders, more efficient multi-camera tokenization (triplane representations, video-level compression via Flex), KV-cache sharing across action experts.
- Templated reasoning — strip uninformative tokens from reasoning traces at training time so the model doesn't burn inference budget on filler like "drive safely, be careful."
- Diffusion-based trajectory decoding — substantially faster than autoregressive trajectory generation, while also improving comfort metrics.
The stack hits roughly real-time inference today. The field-level takeaway: edge latency, long a foreclosing constraint on architectural experimentation, is becoming a manageable engineering parameter. The interesting decisions are now about what representation to use, not whether you can afford to use one at all.
8. Cosmos-Drive-Dreams and the state of AV simulation today
A useful three-bucket framing for where AV simulation sits today came up in the Q&A:
- Testing with neural reconstruction — largely solved; most companies do it.
- Training at production scale — still difficult; the team thinks the field is "on the verge."
- Validation — still open.
Within that, Cosmos-Drive-Dreams (released by NVIDIA earlier this year) is one of the recent examples of using generative AI to scale AV training data, particularly for the long tail. The pipeline generates challenging, multi-view, spatiotemporally consistent driving videos conditioned on HDMap layouts, with controllable variation across weather, time of day, and geographic style. It's built on the Cosmos world foundation models, post-trained for driving, and includes both video generation and LiDAR generation modes.

The empirical results are most pronounced on perception: meaningful F1 gains in 3D lane detection, and clear improvements in 3D object detection across vehicle categories. The pipeline, model weights, dataset, and toolkit are all open-source. For researchers and startups working on perception with limited fleet data, it's a useful release to integrate, regardless of whether you're working on full-stack AV.
9. Behavioral diversity in synthetic data is still the open problem
On where generative simulation hasn't yet delivered, the discussion was direct: policy learning. The framing offered:
"Visually new is easy; behaviorally new is hard. Recreating how a pedestrian moves their torso — that's very hard."
What this means concretely: adding new weather, lighting, and geographic conditions to a dataset clearly helps perception (Cosmos-Drive-Dreams demonstrates this). But moving driving-policy KPIs through generated data requires generating behaviorally novel agents whose distributional shift actually exposes new model weaknesses. Pedestrians who hesitate at the curb, vehicles that change lanes erratically, cyclists who weave through traffic, drivers who misjudge gaps — these remain open research problems.
For researchers entering the field, this is a concrete unsolved problem: agent behavior models that capture the multimodal, partially adversarial, partially cooperative behavior of real road users. It's also a problem that touches reinforcement learning, world models, multi-agent simulation, and human behavior modeling — meaning it has multiple plausible angles of attack from outside the AV community proper.
10. The hardware design cycle as a research target
A side observation that came up during the hardware/software codesign question, worth highlighting for founders. NVIDIA's chip-design lead time means they bet years ahead on what models will look like, and Marco was upfront that "we don't have a clue what models will look like in one to three years… They're wild guesses, but better than no guesses."
The strategic anxiety: if model architectures continue to shift on three-month cycles while chip design stays at multi-year cycles, the design process itself becomes a competitive bottleneck. From the discussion:
"A number of startups are trying to significantly reduce the hardware design process. Because once you have the requirements for your design, you're basically locked in for a year or more, which is a big bet for a company like NVIDIA."
As context for readers, the space that could fall under this description includes AI-augmented electronic design automation — early-stage tools like ChipAgents and Hardian AI, as well as AI features inside the incumbents (Cadence Cerebrus, Synopsys.ai) — and specialized inference silicon that targets narrower model families with faster custom-design loops (Etched, Tenstorrent, Rivos). The signal worth taking is that this space is being tracked from inside one of its largest customers, which is itself a useful market indicator for founders considering this area.
11. Reasoning for embodiment is still in its infancy
To close, a research-direction framing from the discussion:
"Reasoning for embodiment is in its infancy."
The field uses text because it's interpretable and supervised labels exist for it. But humans don't only think in language, and there's no principled reason an embodied policy should either. Open directions that came up include latent reasoning (chains-of-thought in learned continuous representations, which Wenjie flagged as something the team is actively exploring), better architectural priors (vision encoders, multi-camera tokenization), and reasoning forms that aren't linear at all — parallel exploration via diffusion, tree search, self-reflection loops, search in semantic space.
The assessment from the team about where the field sits today: the most effective angle for injecting causal structure into a reasoning model is still the data side, not the architecture or the representation. That's a description of where things are, not a prediction of where they'll stay. For the next year or two, expect most gains to come from better data — labeling pipelines, structured reasoning traces, counterfactual datasets, scenario curation. But this bottleneck isn't permanent, and the teams that are working on the representational and architectural problem now — non-text reasoning, parallel search, diffusion-based thinking, world-model-augmented self-reflection — are positioning for the wave after.
For researchers and founders entering the space, the implicit invitation is to be skeptical of the assumption that text-based linear chain-of-thought is the right scaffold for embodied AI. It's the scaffold we have. It's not necessarily the scaffold we'll end up with.
Why this matters
A throughline across the discussion: much of the active work in reasoning-VLAs right now isn't about model size or architecture novelty. It's about the infrastructure of reasoning — how you build the data that teaches it, how you anchor it to action, how you make it adaptive and counterfactual rather than descriptive, how you evaluate it where it actually matters, and how you generate the long-tail scenarios that stretch it.
The Alpamayo team is opening up a substantial part of that infrastructure over the coming weeks. If you're building in or adjacent to this space, the upcoming releases (model weights, autolabeling pipeline, reasoning labels, AlpaSim expansion) are a good moment to integrate.


